
Creating LLM Agents for RAG: a detailed guide to architecture, development, and Application
Content
What is RAG and why has it become a key element of modern AI systems?
Understanding LLM Agents
Agent components: brain, memory, planning
Tools for developing LLM and RAG agents
Configuring the environment for creating a RAG agent
Preparation of documents
RAG architecture: a scheme for practical implementation
Building a search quality control chain
Querying the system and working with the context
Creating an LLM Agent
Agent architecture: logic, interaction, tools
Improving the RAG agent using advanced techniques
Multi-agent systems: relevance and quality assessment
Future directions and key challenges
Technical application: an example of the implementation of a RAG agent in Python
What is RAG and why has it become a key element of modern AI systems?
Retrieval-Augmented Generation (RAG) allows the language model to access external data and generate responses not only based on its own parameters, but also based on documents, internal knowledge bases and regulations. This approach reduces the likelihood of errors and ensures reliable conclusions, especially in a corporate environment where accuracy and control requirements are high.
RAG has become the main tool for companies working with large amounts of documents: it speeds up information retrieval, automates analytical tasks, and improves the quality of customer support. In a number of practical implementations, RAG has reduced the processing time of questions by tens of percent, as well as stabilized the quality of responses.
Understanding LLM Agents
LLM agents extend the capabilities of regular RAG. If RAG answers the question, then the agent is able to plan the work, perform several steps, use tools, check the quality of results and adjust the strategy.
In legal and technical expertise, such systems allow you to automate the analysis of documents, identify inconsistencies and make recommendations. This reduces the burden on employees and increases the accuracy of information processing.
Agent components: brain, memory, planning
Agent (brain)
Manages the process of solving the problem: interprets the request, selects tools, forms a strategy and evaluates the result.
Memory
The memory system includes short-term context, working memory, and long-term vector storage. In the RAG architecture, vector memory provides access to corporate documents and knowledge.
Planning
The scheduler determines the sequence of actions, monitors the execution of steps, and analyzes the completion of the task. This ensures the stability and predictability of the agent's behavior.
Tools for developing LLM and RAG agents
The following categories of tools are used to build RAG agents:
They provide development flexibility, allow you to add tools, form chains of reasoning, and implement complex search scenarios.
Configuring the environment for creating a RAG agent
Usually Python, LangChain or LlamaIndex and a vector database server are used. Industrial implementation takes into account security requirements, logging, and the possibility of horizontal scaling.
Preparation of documents
Document preparation includes file parsing, cleaning, fragmentation, and vectorization. The fragment size in the range of 500-1500 tokens allows you to keep the meaning and improve the accuracy of the search.
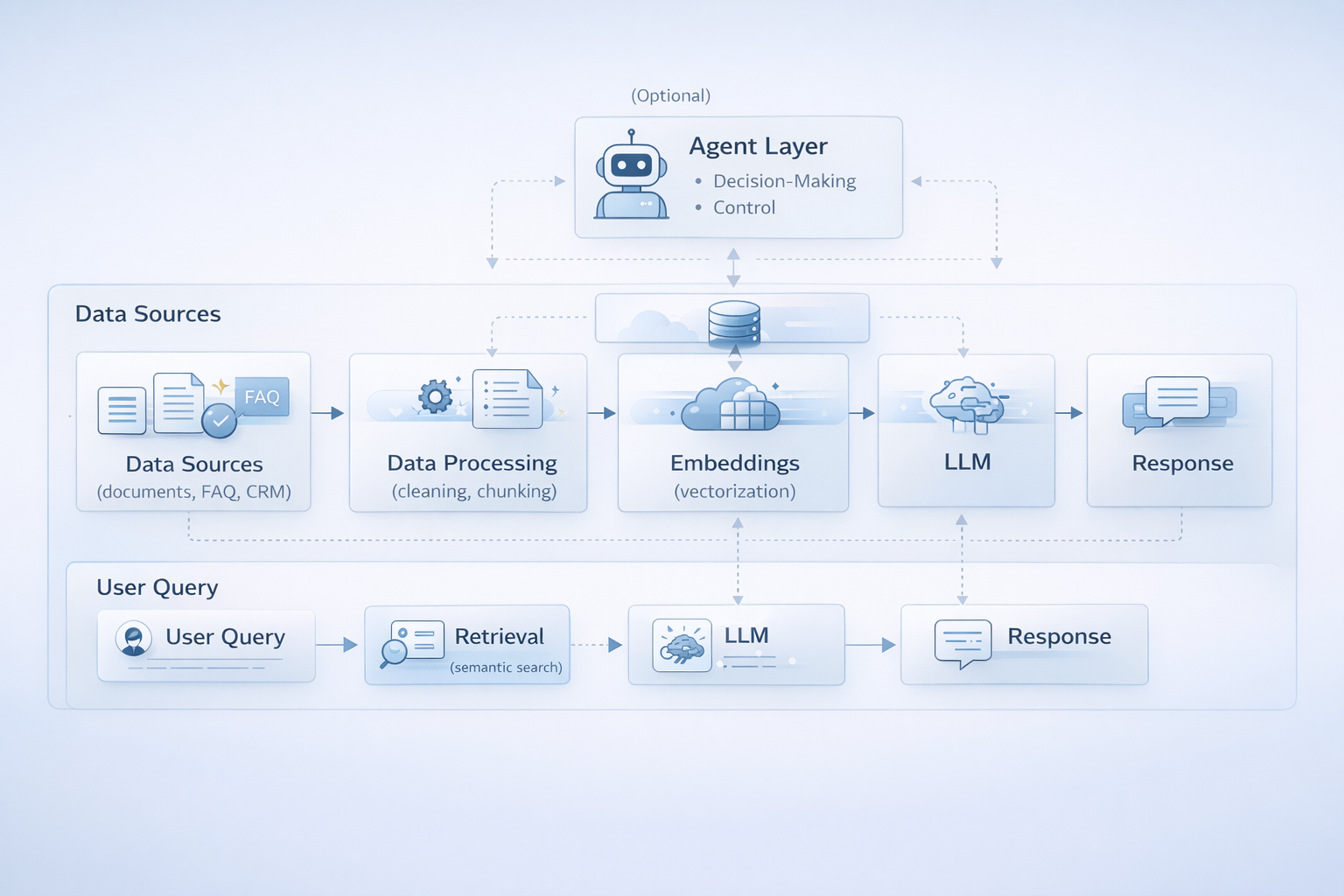
RAG architecture: a scheme for practical implementation
To visualize the RAG architecture, we recommend a diagram that includes:
This diagram demonstrates the complete data path from the document to the finished response.
Building a search quality control chain
To improve the search quality, a combination is used:
This approach significantly improves accuracy and reduces the chance of getting irrelevant fragments.
Querying the system and working with the context
The request template combines the instruction, the response format, and the context transmitted from the search. This allows the model to work steadily and eliminates false conclusions with a lack of information.
Creating an LLM Agent
The agent's work includes several stages, which are presented in a list:
Analyzing the query, choosing a strategy, and determining the need for a search.
Obtaining documents from vector memory and evaluating their sufficiency.
Formation of a draft response and initial verification of correctness.
If necessary, refine the query, re-search, and improve the response.
A couple of techniques
Automatic request extension
Task decomposition
Agent architecture: logic, interaction, tools
It is recommended to add a diagram for the article, illustrating:
The diagram helps the reader see how search, reasoning, and final response generation are related.
Improving the RAG agent using advanced techniques
Semantic search for DPR
Using separate encoders for queries and documents improves the quality of matching.
Request Extension
Allows the agent to independently refine the wording and increase the completeness of the search.
Iterative refinement
Combines a draft response, quality control, and adjustments to achieve a more accurate result.
Multi-agent systems: relevance and quality assessment
In complex scenarios, several agents are used: one evaluates the relevance of documents, the other checks the logic of the response, and the third verifies facts with sources.
The diagram of such a solution includes an Orchestrator (coordinator) and three modules: Search Agent, Answer Agent, Review Agent.
Future directions and key challenges
The development of RAG agents is moving in three directions:
increasing the depth of search and hybrid matching methods;
development of self-learning and autonomous memory updating;
integration of models capable of complex multicore reasoning.
The main challenge remains the same: ensuring the quality, explainability, and controllability of AI systems in an environment with high reliability requirements.
Technical application: an example of the implementation of a RAG agent in Python
This example demonstrates the basic framework of a RAG agent, which includes:
It can serve as a starting point for building a complete system.
import os
from typing import List, Tuple
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
load_dotenv()
llm = ChatOpenAI(
model="gpt-4.1-mini",
temperature=0.1,
)
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
def build_vector_store(texts: List[str], persist_dir: str = "./rag_index") -> Chroma:
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
docs: List[Document] = []
for i, t in enumerate(texts):
for chunk in splitter.split_text(t):
docs.append(Document(page_content=chunk, metadata={"source_id": i}))
vector_store = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory=persist_dir,
)
vector_store.persist()
return vector_store
def retrieve_relevant_docs(vector_store: Chroma, query: str, k: int = 4) -> List[Document]:
return vector_store.similarity_search(query, k=k)
SYSTEM_PROMPT = """
Ты — экспертный ассистент, который отвечает строго на основе предоставленных документов.
Если информации не хватает, сообщи об этом честно.
"""
def format_context(docs: List[Document]) -> str:
parts = []
for idx, d in enumerate(docs, start=1):
parts.append(f"[Фрагмент {idx}]\n{d.page_content}\n")
return "\n".join(parts)
def agent_answer(vector_store: Chroma, user_query: str) -> Tuple[str, float]:
docs = retrieve_relevant_docs(vector_store, user_query, k=4)
context_text = format_context(docs)
prompt = f"""
{SYSTEM_PROMPT}
Вопрос пользователя: {user_query}
Контекст:
{context_text}
Сначала дай ответ, затем оцени уверенность (0–1).
Формат:
Ответ: <текст>
Уверенность: <число>
"""
resp = llm.invoke(prompt)
text = resp.content
confidence = 0.5
for line in text.splitlines():
if "Уверенность:" in line:
try:
confidence = float(line.split("Уверенность:")[1].strip())
except:
pass
return text, confidence
if __name__ == "__main__":
corporate_docs = [
"Регламент оценки рисков...",
"Порядок инспекции оборудования...",
"Инструкция регистрации инцидентов..."
]
vs = build_vector_store(corporate_docs)
query = "Как проводится ежегодная техническая инспекция?"
answer, conf = agent_answer(vs, query)
print(answer)
print("Уверенность:", conf)