
Создание LLM-агентов для RAG: подробное руководство по архитектуре, разработке и применению


Содержание
-
Что такое RAG и почему он стал ключевым элементом современных ИИ-систем
-
Техническое приложение: пример реализации RAG-агента на Python
Что такое RAG и почему он стал ключевым элементом современных ИИ-систем
Retrieval-Augmented Generation (RAG) позволяет языковой модели получать доступ к внешним данным и формировать ответы не только на основе собственных параметров, но и опираясь на документы, внутренние базы знаний и регламенты. Такой подход снижает вероятность ошибок и обеспечивает достоверность выводов — особенно в корпоративной среде, где требования к точности и контролю высоки.
RAG стал основным инструментом компаний, работающих с большими массивами документов: он ускоряет поиск информации, автоматизирует аналитические задачи и повышает качество клиентской поддержки. В ряде практических внедрений RAG позволил сократить время обработки вопросов на десятки процентов, а также стабилизировать качество ответов.
Понимание агентов LLM
Агенты LLM расширяют возможности обычного RAG. Если RAG отвечает на вопрос, то агент способен планировать работу, выполнять несколько шагов, использовать инструменты, проверять качество результатов и корректировать стратегию.
В юридической и технической экспертизе такие системы позволяют автоматизировать анализ документов, выявление несоответствий и формирование рекомендаций. Это снижает нагрузку на сотрудников и повышает точность обработки информации.
Компоненты агента: мозг, память, планирование
Агент (мозг)
Управляет процессом решения задачи: интерпретирует запрос, выбирает инструменты, формирует стратегию и оценивает результат.
Память
Система памяти включает краткосрочный контекст, рабочую память и долгосрочное векторное хранилище. В RAG-архитектуре именно векторная память обеспечивает доступ к корпоративным документам и знаниям.
Планирование
Планировщик определяет последовательность действий, контролирует выполнение шагов и анализирует завершённость задачи. Это обеспечивает устойчивость и предсказуемость поведения агента.
Инструменты для разработки агентов LLM и RAG
Для построения RAG-агентов используется набор инструментов, покрывающий весь процесс — от хранения знаний до генерации ответа.
Фреймворки (логика и оркестровка)
LangChain, LangGraph, LlamaIndex. Отвечают за управление пайплайном: поиск, обработка, вызов LLM и агентную логику.
Векторные хранилища (память)
Chroma, Qdrant, Pinecone. Хранят embeddings и обеспечивают быстрый семантический поиск.
Модели эмбеддингов (поиск по смыслу)
OpenAI text-embedding-3, bge-large, E5. Определяют, насколько точно система находит релевантные данные.
LLM-модели (генерация ответа)
ChatGPT 5.4, Claude Opus 4.6, GPT-4.1, Claude 3.5, DeepSeek R1, LLaMA. Формируют итоговый ответ на основе найденного контекста.
Модели reranking (точность)
bge-reranker-large, Cohere Rerank. Улучшают качество выдачи, отбирая наиболее релевантные фрагменты перед передачей в LLM.
Ключевой момент. RAG — это не одна модель, а связка компонентов. Качество системы в первую очередь определяется данными и поиском, а не только выбранной LLM.
Настройка среды для создания RAG-агента
Обычно используется Python, LangChain или LlamaIndex и сервер векторной базы данных. При промышленном внедрении учитываются требования безопасности, логирование и возможность горизонтального масштабирования.
Подготовка документов
Подготовка документов включает разбор файлов, очистку, разбиение на фрагменты и векторизацию. Размер фрагмента в диапазоне 500–1500 токенов позволяет сохранить смысл и повысить точность поиска.
Архитектура RAG: схема для практического внедрения
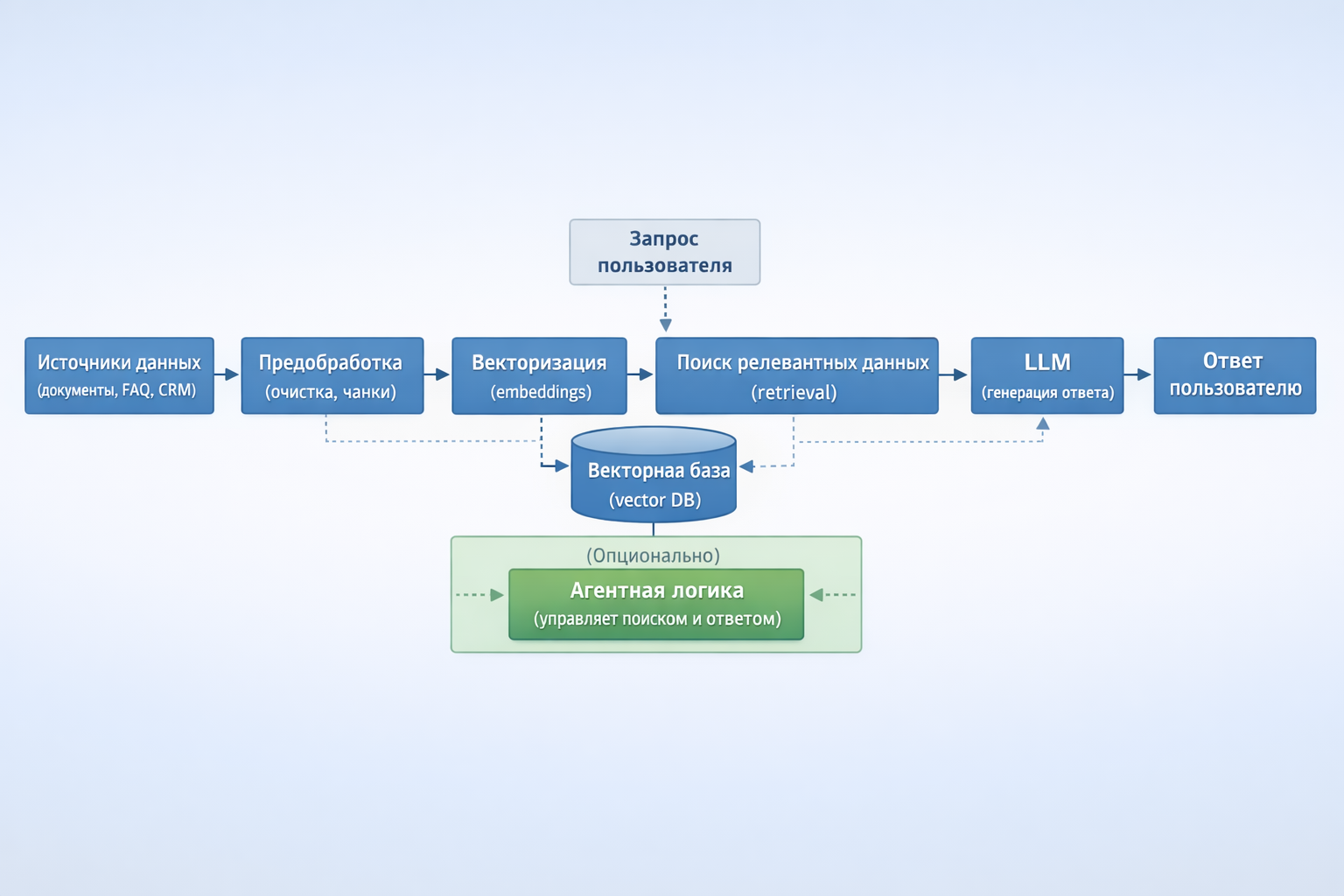
На практике архитектура RAG-системы делится на два независимых контура: подготовка данных и обработка пользовательского запроса. Это разделение критично — именно оно позволяет системе быть одновременно точной, масштабируемой и управляемой.
Контур подготовки данных (offline)
На этом этапе система работает без участия пользователя. В нее загружаются источники знаний: документы, инструкции, база FAQ, данные из CRM или других внутренних систем. Далее данные очищаются, нормализуются и разбиваются на небольшие смысловые фрагменты (чанки).
Каждый фрагмент преобразуется в векторное представление (embeddings) — числовую форму, которая позволяет находить тексты с похожим смыслом. После этого данные сохраняются во векторной базе.
На практике именно этот этап чаще всего определяет качество всей системы: если данные плохо подготовлены, даже сильная LLM не сможет давать точные ответы.
Контур обработки запроса (online)
Когда пользователь задает вопрос, система не передает его напрямую в LLM. Вместо этого сначала выполняется поиск релевантных фрагментов в базе знаний.
Процесс выглядит так:
- запрос пользователя также преобразуется в вектор;
- система находит ближайшие по смыслу фрагменты;
- при необходимости применяется дополнительная фильтрация или reranking;
- найденный контекст передается в LLM вместе с инструкцией.
LLM формирует ответ, опираясь не на «общие знания», а на конкретные данные компании. Это снижает количество ошибок и делает ответы предсказуемыми.
Роль агентной логики (надстройка)
В более продвинутых системах между поиском и генерацией появляется агентный слой. Он управляет процессом:
- решает, достаточно ли найденного контекста;
- инициирует повторный поиск;
- уточняет запрос пользователя;
- выбирает источник данных;
- может вызывать внешние сервисы.
За счет этого RAG превращается из «поиска + генерации» в управляемую систему принятия решений.
Упрощенная схема архитектуры
RAG-система в базовом виде выглядит так:
- Источники данных → обработка → векторизация → векторная база → поиск → LLM → ответ пользователю
При добавлении агентного слоя схема усложняется, но становится более гибкой и точной.
Ключевые выводы для внедрения
- качество данных важнее модели;
- RAG — это не только LLM, а полноценная архитектура;
- разделение на offline/online — обязательное условие масштабирования;
- агентный слой — следующий шаг развития системы.
Построение цепочки контроля качества поиска
Для повышения качества поиска применяется комбинация:
— классического поиска (BM25),
— семантического поиска embeddings,
— дополнительной сортировки reranker-моделью.
Этот подход существенно улучшает точность и снижает вероятность попадания нерелевантных фрагментов.
Запрос к системе и работа с контекстом
Шаблон запроса объединяет инструкцию, формат ответа и контекст, переданный из поиска. Это позволяет модели работать устойчиво и исключает ложные выводы при недостатке информации.
Создание агента LLM
Работа агента включает несколько этапов, которые представлены списком:
-
Анализ запроса, выбор стратегии и определение необходимости поиска.
-
Получение документов из векторной памяти и оценка их достаточности.
-
Формирование чернового ответа и первичная проверка корректности.
-
При необходимости уточнение запроса, повторный поиск и улучшение ответа.
Пара технических приёмов
-
Автоматическое расширение запроса
Агент дополняет исходный запрос синонимами и связанными терминами, повышая полноту поиска. -
Декомпозиция задачи
Агент разделяет сложный вопрос на подзадачи: это позволяет получить структурированный и более точный ответ.
Архитектура агента
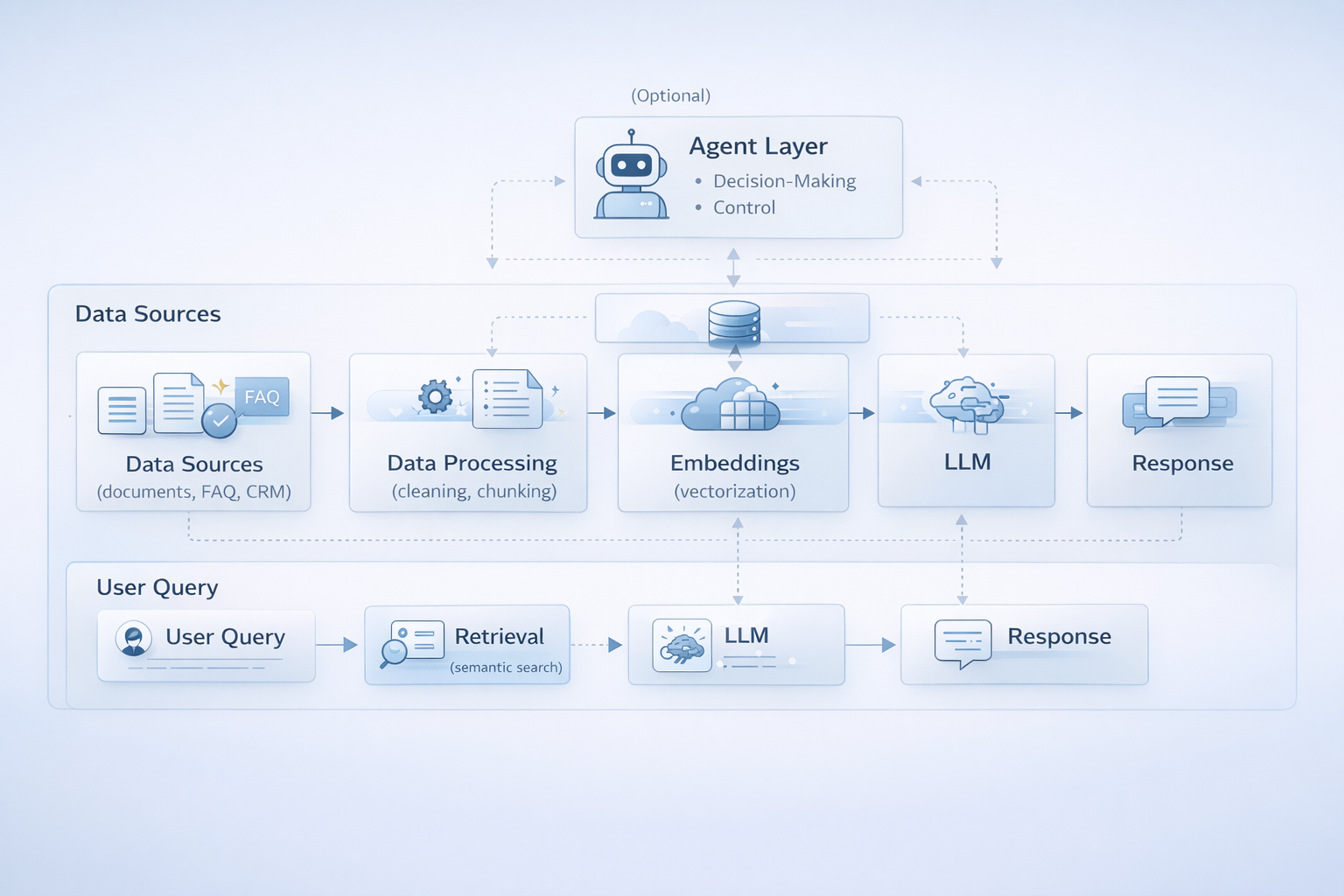
На практике архитектура RAG-агента строится как последовательная цепочка обработки данных и запроса пользователя. Сначала в систему поступают источники знаний: внутренние документы, регламенты, инструкции, база FAQ, CRM-данные или другие корпоративные материалы. Затем эти данные проходят предварительную обработку: очищаются, разбиваются на смысловые фрагменты и преобразуются в векторные представления для последующего поиска. Такой подход соответствует общей логике RAG, где ключевую роль играют внешние документы, векторная память и контроль качества поиска.
После подготовки данных они сохраняются во векторном хранилище. Когда пользователь задает вопрос, система не отправляет его сразу в LLM, а сначала ищет наиболее релевантные фрагменты в базе знаний. Для повышения точности этот этап может включать не только семантический поиск по embeddings, но и дополнительную проверку через гибридный поиск или reranker. Только после этого найденный контекст вместе с инструкцией передается языковой модели, которая формирует итоговый ответ. Именно такая цепочка позволяет снизить число неточных ответов и сделать работу системы более устойчивой в реальных бизнес-сценариях.
Если описать архитектуру совсем просто, она выглядит так: источники данных → обработка и разбиение документов → векторизация → векторная база → поиск релевантных фрагментов → LLM → готовый ответ пользователю. Если в систему добавляется агентный слой, между поиском и генерацией ответа появляется дополнительная логика: агент анализирует запрос, решает, нужен ли повторный поиск, хватает ли найденного контекста, нужно ли уточнить вопрос или перепроверить результат. За счет этого обычный RAG превращается в более гибкую систему, которая умеет не только находить знания, но и управлять процессом ответа.
Улучшение RAG-агента с помощью передовых методов
Семантический поиск DPR
Использование отдельных энкодеров для запросов и документов улучшает качество сопоставления.
Расширение запроса
Позволяет агенту самостоятельно уточнять формулировки и повышать полноту поиска.
Итеративное уточнение
Объединяет черновой ответ, проверку качества и корректировки для достижения более точного результата.
Многоагентные системы: оценка релевантности и качества
В сложных сценариях используется несколько агентов: один оценивает релевантность документов, другой проверяет логику ответа, третий сверяет факты с источниками.
Диаграмма такого решения включает Orchestrator (координатор) и три модуля: Search Agent, Answer Agent, Review Agent.
Будущие направления и ключевые вызовы
Развитие RAG-агентов движется в трёх направлениях:
-
повышение глубины поиска и гибридных методов сопоставления;
-
развитие самообучения и автономного обновления памяти;
-
интеграция моделей, способных к сложному многокроковому рассуждению.
Основной вызов остаётся прежним: обеспечение качества, объяснимости и контролируемости работы ИИ-систем в среде с высокими требованиями к надёжности.
Техническое приложение: пример реализации RAG-агента на Python
Этот пример демонстрирует базовый каркас RAG-агента, включающий ключевые этапы разработки ПО: подготовку документов, создание векторного индекса, поиск релевантных фрагментов, формирование ответа и простейшую самопроверку.
— подготовку документов,
— создание векторного индекса,
— поиск релевантных фрагментов,
— формирование ответа,
— простейшую self-evaluation.
Он может служить отправной точкой для построения полноценной системы.
import os
import re
from pathlib import Path
from typing import List, Tuple
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise RuntimeError("Не найден OPENAI_API_KEY. Добавьте его в .env файл.")
LLM_MODEL = "gpt-4.1-mini"
EMBEDDING_MODEL = "text-embedding-3-small"
PERSIST_DIR = "./rag_index"
llm = ChatOpenAI(
model=LLM_MODEL,
temperature=0.1,
)
embeddings = OpenAIEmbeddings(
model=EMBEDDING_MODEL
)
SYSTEM_PROMPT = """
Ты — экспертный ассистент, который отвечает строго на основе предоставленных документов.
Если в документах недостаточно информации, сообщи об этом честно.
Не придумывай факты и не додумывай детали.
Сначала дай краткий и точный ответ, затем оцени уверенность по шкале от 0 до 1.
Формат ответа:
Ответ: <текст>
Уверенность: <число>
""".strip()
def build_vector_store(
texts: List[str],
source_names: List[str] | None = None,
persist_dir: str = PERSIST_DIR,
) -> Chroma:
"""
Создает векторное хранилище из списка текстов.
"""
persist_path = Path(persist_dir)
persist_path.mkdir(parents=True, exist_ok=True)
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
)
docs: List[Document] = []
for i, text in enumerate(texts):
source_name = source_names[i] if source_names and i < len(source_names) else f"Документ {i + 1}"
chunks = splitter.split_text(text)
for chunk_index, chunk in enumerate(chunks, start=1):
docs.append(
Document(
page_content=chunk,
metadata={
"source_id": i,
"source_name": source_name,
"chunk_index": chunk_index,
},
)
)
vector_store = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory=str(persist_path),
)
vector_store.persist()
return vector_store
def retrieve_relevant_docs(
vector_store: Chroma,
query: str,
k: int = 4,
) -> List[Document]:
"""
Возвращает список наиболее релевантных документов.
"""
return vector_store.similarity_search(query, k=k)
def format_context(docs: List[Document]) -> str:
"""
Формирует текстовый контекст для LLM.
"""
if not docs:
return "Релевантные фрагменты не найдены."
parts = []
for idx, doc in enumerate(docs, start=1):
source_name = doc.metadata.get("source_name", f"Документ {idx}")
chunk_index = doc.metadata.get("chunk_index", "?")
parts.append(
f"[Фрагмент {idx} | Источник: {source_name} | Чанк: {chunk_index}]\n"
f"{doc.page_content}\n"
)
return "\n".join(parts)
def parse_llm_response(text: str) -> Tuple[str, float]:
"""
Извлекает текст ответа и уверенность из ответа модели.
"""
answer_match = re.search(r"Ответ:\s*(.*?)(?:\nУверенность:|\Z)", text, re.DOTALL)
confidence_match = re.search(r"Уверенность:\s*([0-9]*\.?[0-9]+)", text)
answer = answer_match.group(1).strip() if answer_match else text.strip()
confidence = 0.5
if confidence_match:
try:
confidence = float(confidence_match.group(1))
confidence = max(0.0, min(1.0, confidence))
except ValueError:
pass
return answer, confidence
def agent_answer(vector_store: Chroma, user_query: str, k: int = 4) -> Tuple[str, float]:
"""
Выполняет поиск контекста, обращается к LLM и возвращает итоговый ответ с уверенностью.
"""
docs = retrieve_relevant_docs(vector_store, user_query, k=k)
if not docs:
return "Не удалось найти релевантную информацию в базе знаний.", 0.0
context_text = format_context(docs)
prompt = f"""
{SYSTEM_PROMPT}
Вопрос пользователя:
{user_query}
Контекст:
{context_text}
""".strip()
response = llm.invoke(prompt)
raw_text = response.content if isinstance(response.content, str) else str(response.content)
answer, confidence = parse_llm_response(raw_text)
return answer, confidence
if __name__ == "__main__":
corporate_docs = [
"Регламент оценки рисков: ежегодная техническая инспекция проводится комиссией один раз в год. "
"Перед проверкой формируется перечень оборудования, назначаются ответственные и подготавливается журнал осмотра.",
"Порядок инспекции оборудования: в ходе инспекции проверяются узлы, техническое состояние, "
"наличие дефектов, сроки обслуживания и соответствие требованиям безопасности.",
"Инструкция регистрации инцидентов: по итогам инспекции выявленные отклонения фиксируются в журнале, "
"назначаются корректирующие действия и ответственные лица."
]
source_names = [
"Регламент оценки рисков",
"Порядок инспекции оборудования",
"Инструкция регистрации инцидентов",
]
vector_store = build_vector_store(
texts=corporate_docs,
source_names=source_names,
persist_dir=PERSIST_DIR,
)
query = "Как проводится ежегодная техническая инспекция?"
answer, confidence = agent_answer(vector_store, query, k=4)
print("Вопрос:", query)
print("Ответ:", answer)
print("Уверенность:", confidence)
 Автор
Anton Amosov
Автор
Anton Amosov


Читайте также
Разработка MAX-ботов: новый национальный мессенджер для бизнеса
Как точно оценить стоимость разработки корпоративного веб‑приложения: руководство для бизнеса
